手写图片的自动识别


因为我最近在学习结合框架的开发,所以我的第一次测试选取的是实现上传页面的前后端书写。
pytesseract介绍
pytesseract是基于Python的OCR工具, 底层使用的是Google的Tesseract-OCR 引擎,支持识别图片中的文字,支持jpeg, png, gif, bmp, tiff等图片格式。
OCR介绍
OCR(Optical character recognition,光学字符识别)是一种将图像中的手写字或者印刷文本转换为机器编码文本的技术。通过数字方式存储文本数据更容易保存和编辑,可以存储大量数据,比如1G的硬盘可以存储数百万本书。
OCR技术可以将图片,纸质文档中的文本转换为数字形式的文本。OCR过程一般包括以下步骤:
- 图像预处理
- 文本定位
- 字符分割
- 字符识别 最初由惠普开发,后来Google赞助的开源OCR引擎 tesseract 提供了比较精确的文字识别API,本文将要介绍的Python库Pytesseract就是基于Tesseract-OCR 引擎。
pytesseract的安装以及环境配置
参考文章



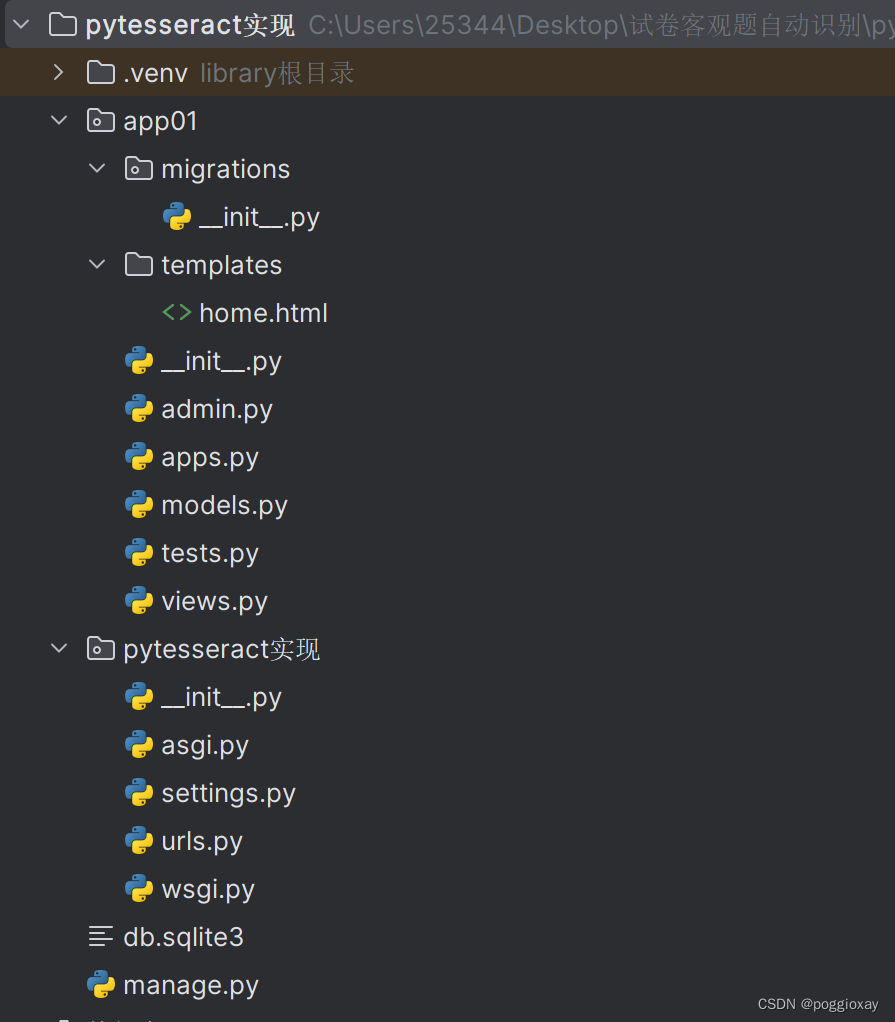
目录结构
url.py
view.py
home.html
该方法虽然可以实现电子版文字、图片和字符的分析,但是对于手写体,还是存在一些不足,无法识别。
是一个基于飞桨开发的多语言工具包,它具备实用性和轻量级的特点,支持超过80种语言的文字识别。 的一大特色是提供了一系列预训练模型,这些模型包括文本检测、文本方向分类和文本识别等多种类型,以实现高精度的效果。
PaddleOCR模型训练源码
分别上传下面两张图片


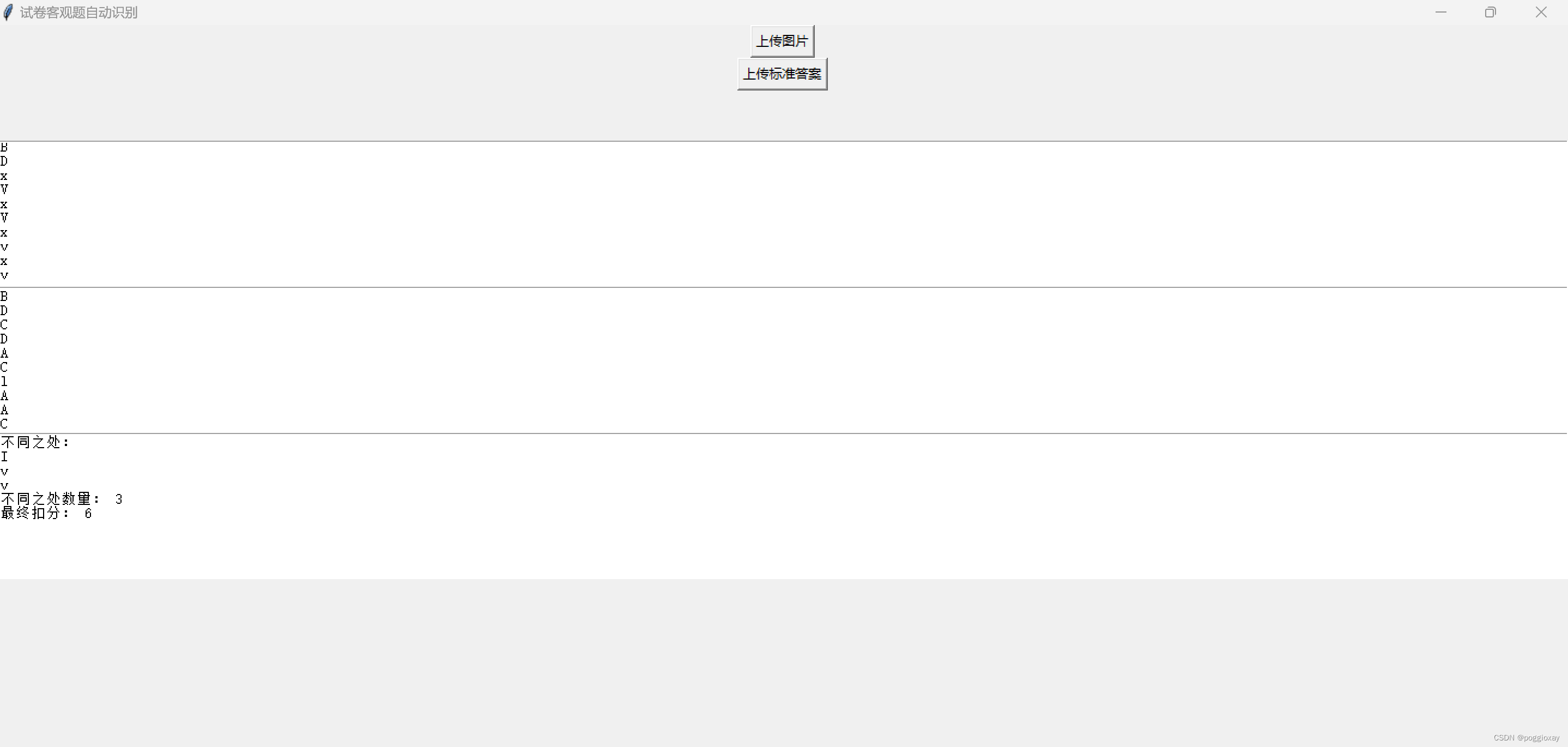
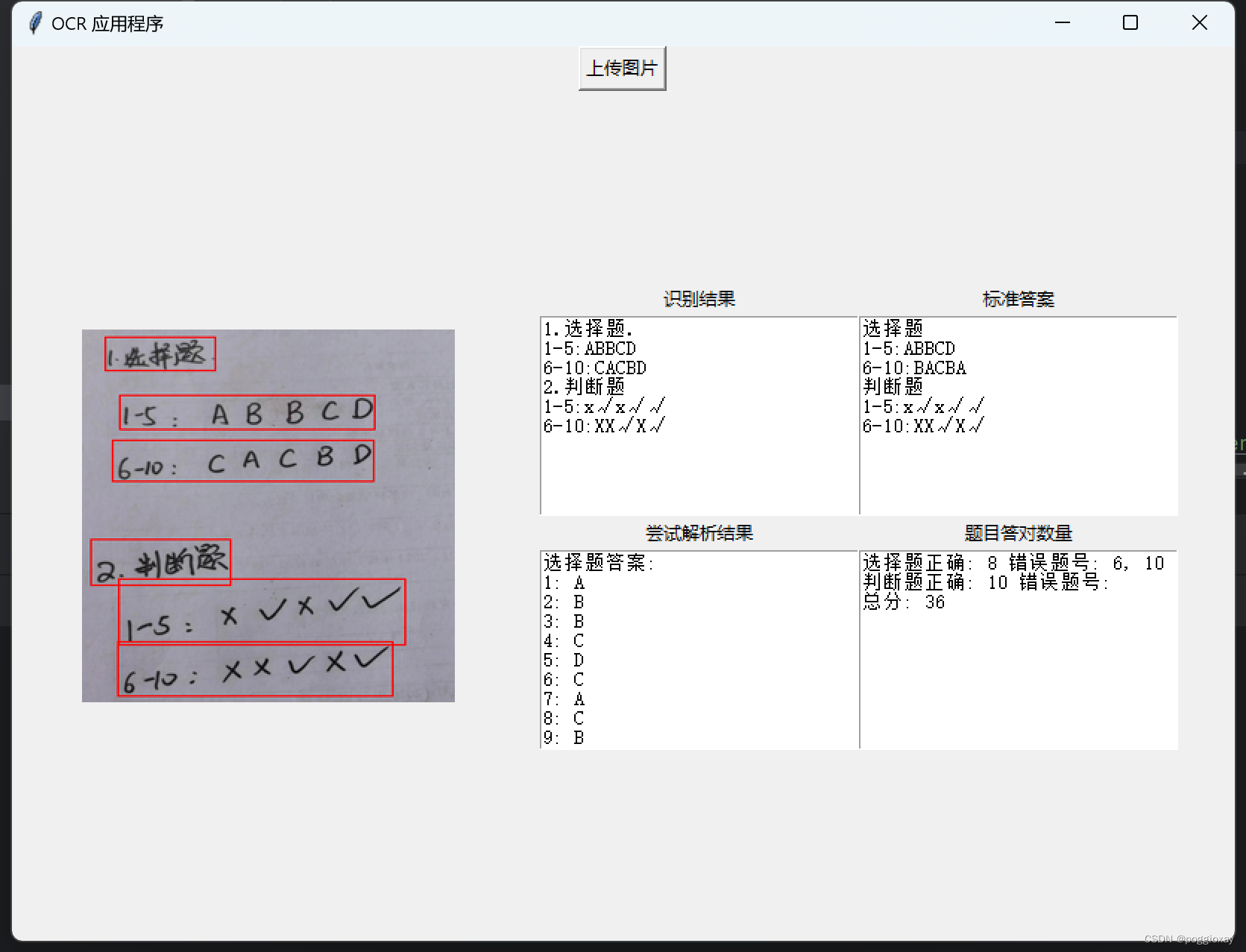
该方法比较于方法1,可以很好的识别手写图片。但是我们可以清楚的看到,对于数字的分析,仍然还会有一些出入,如上面示例中的识别为,书写字体较斜而影响识别顺序;对于和的识别,经过多次测试,我发现大部分的都会被识别为,所以将代码中的正则表达式修改为,但是还会出现识别不出来的情况。 在这里我遇到的难题主要是书写字体较斜而影响识别顺序,导致直接影响与标准答案的对比。
中第三方库非常多,比如、、等等。 是一个用 编写的 库,用于识别图像中的文字并输出为文本,支持 80 多种语言。 检测部分使用算法,识别模型为,由3个组件组成:特征提取、序列标记、解码,整个深度学习过程基于实现。
这段代码用于从指定路径读取图片,对其进行预处理(包括灰度转换和二值化),并通过轮廓检测识别出图片中的字符。随后,使用库对处理过的图像进行文字识别,并将识别结果输出显示。但是,需要注意的是,若在正常的网络下加载运行,时间比较久,建议使用代理打开模式的网络情况下运行。
原始图片:

处理后的图片: 
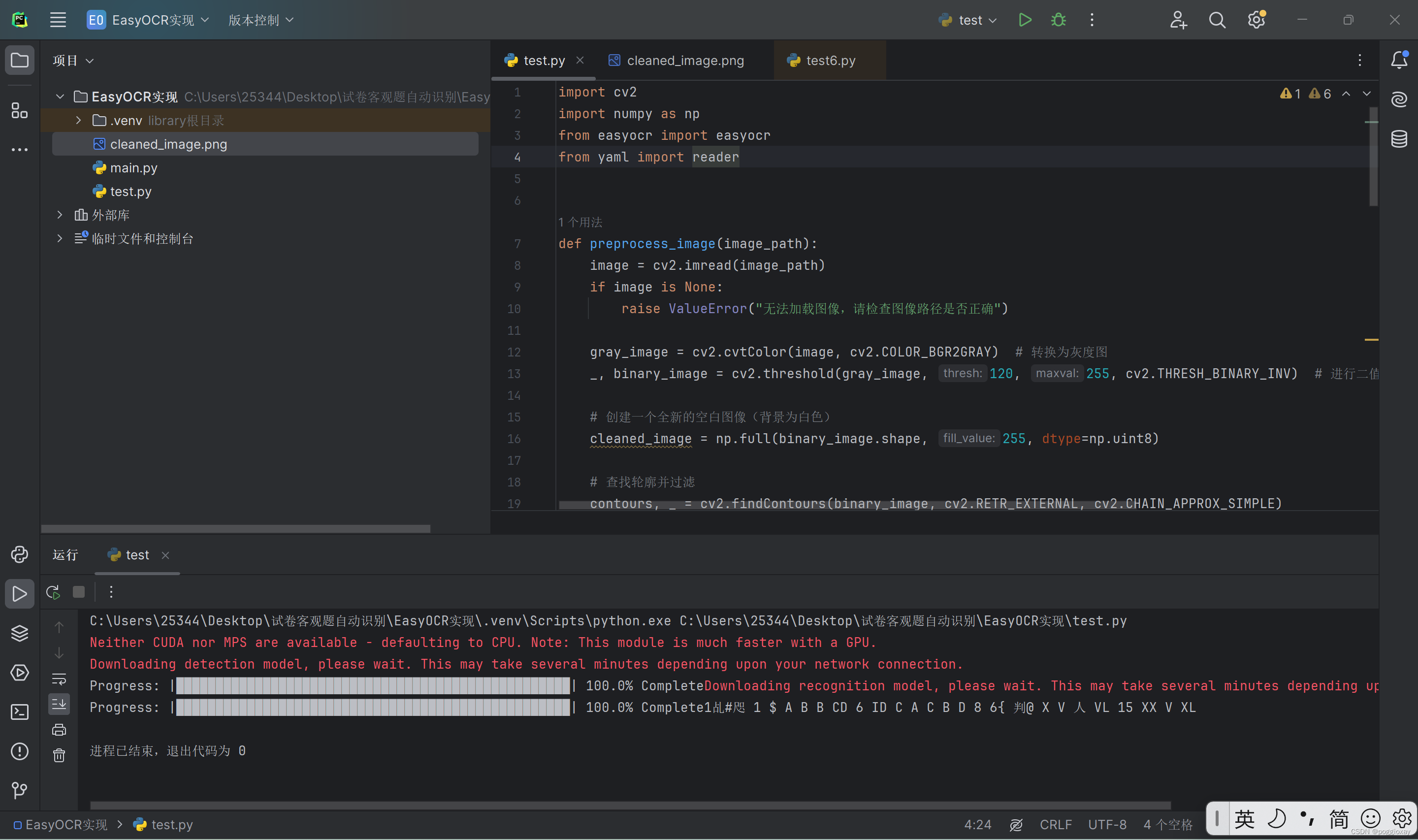
从它的运行结果来看,将图片进行处理后,对于字母识别情况不会因为书写字体较斜而影响识别顺序,比较于前一种效果较好。对于字符和的识别方面,比较于前一种较差。 在这里我遇到的难题是:在这三种模型中,无法找到一个较好的模型可以准确识别字符和。
由于还没有系统的学习过机器学习,所以这个过程还有很多不足,在接下来的空闲时间里,我会继续系统的学习机器学习来尝试训练模型。
参考文章
文件目录
运行结果
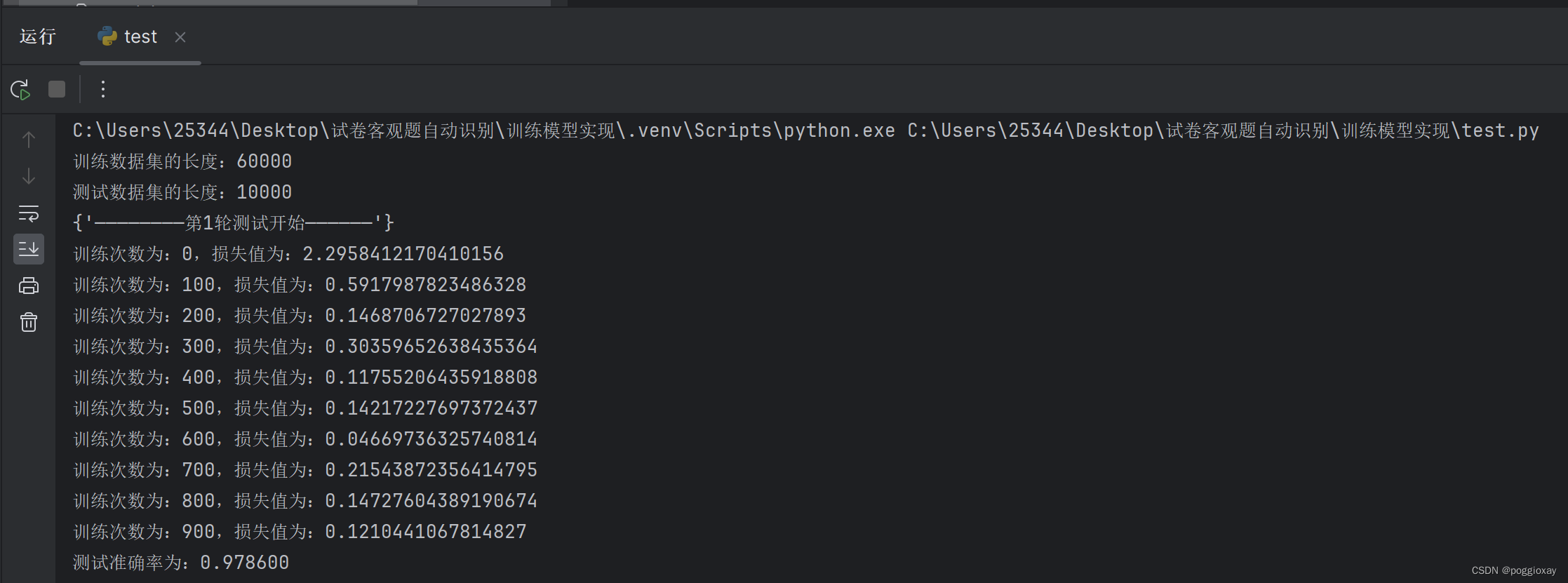
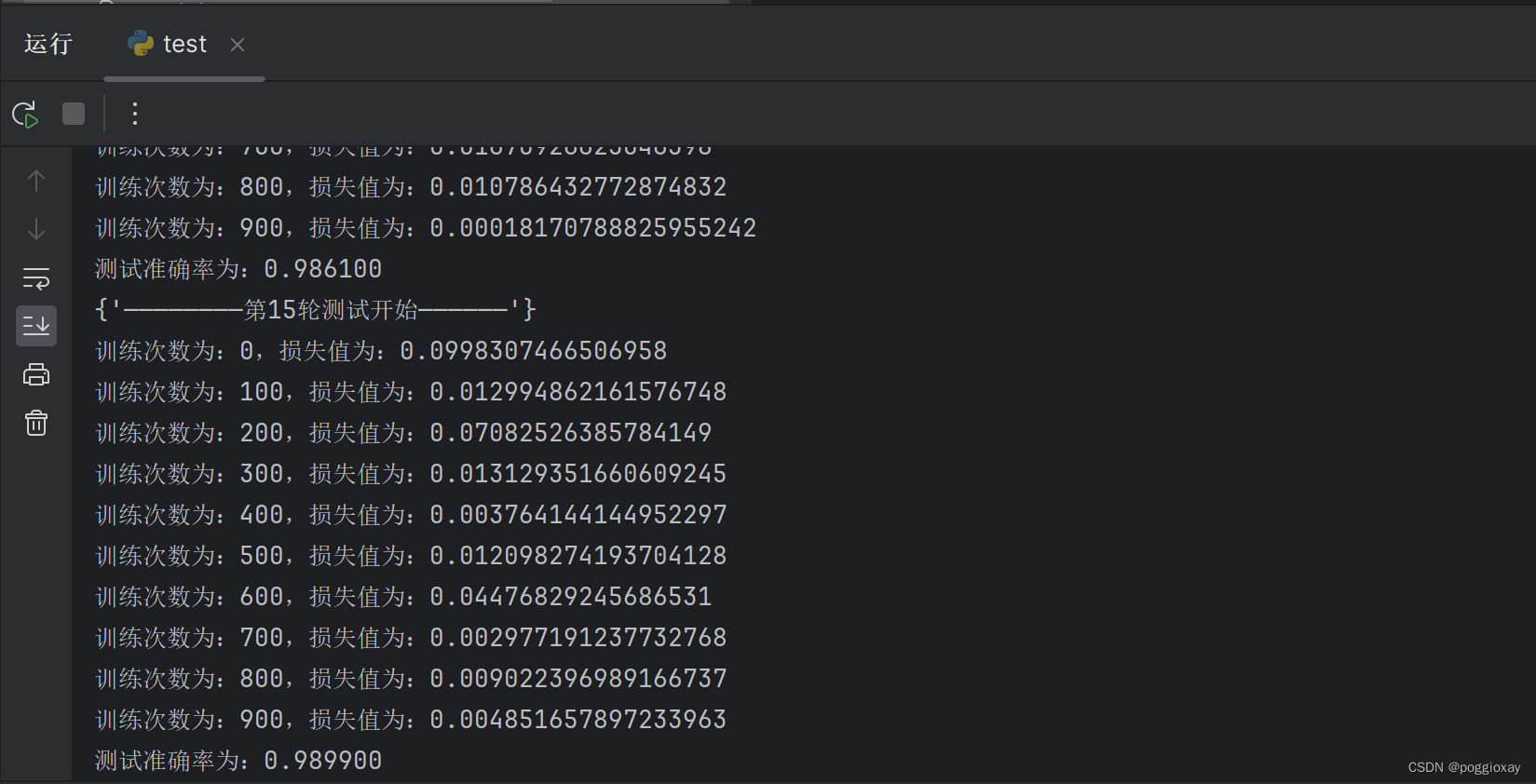 从第1次到第15次,损失值逐渐减小,准确率逐渐增加
从第1次到第15次,损失值逐渐减小,准确率逐渐增加
上传图片: 
运行结果:

可以看到识别的数字很乱,且这段代码的缺点在于每识别一次图片,该模型就会从第一次开始训练模型,耗费时间较长。
运行代码
testnum.py
这段代码首先训练一个简单的神经网络来识别数据集中的手写数字,其次使用一个方法来分割图片中的各个数字,分割每个数字后,使用你现有的模型逐个进行识别。
testnum1.py
参考文章
参考链接
经过测试一些常见付费文字识别的API,例如百度、阿里云,最终选择百度的OCR识别手写字模型。
标准答案一栏需要自己手动输入,在第二次程序打开时,会自动读取存储的标准答案;在修改标准答案后,也可以自动存储到文件。 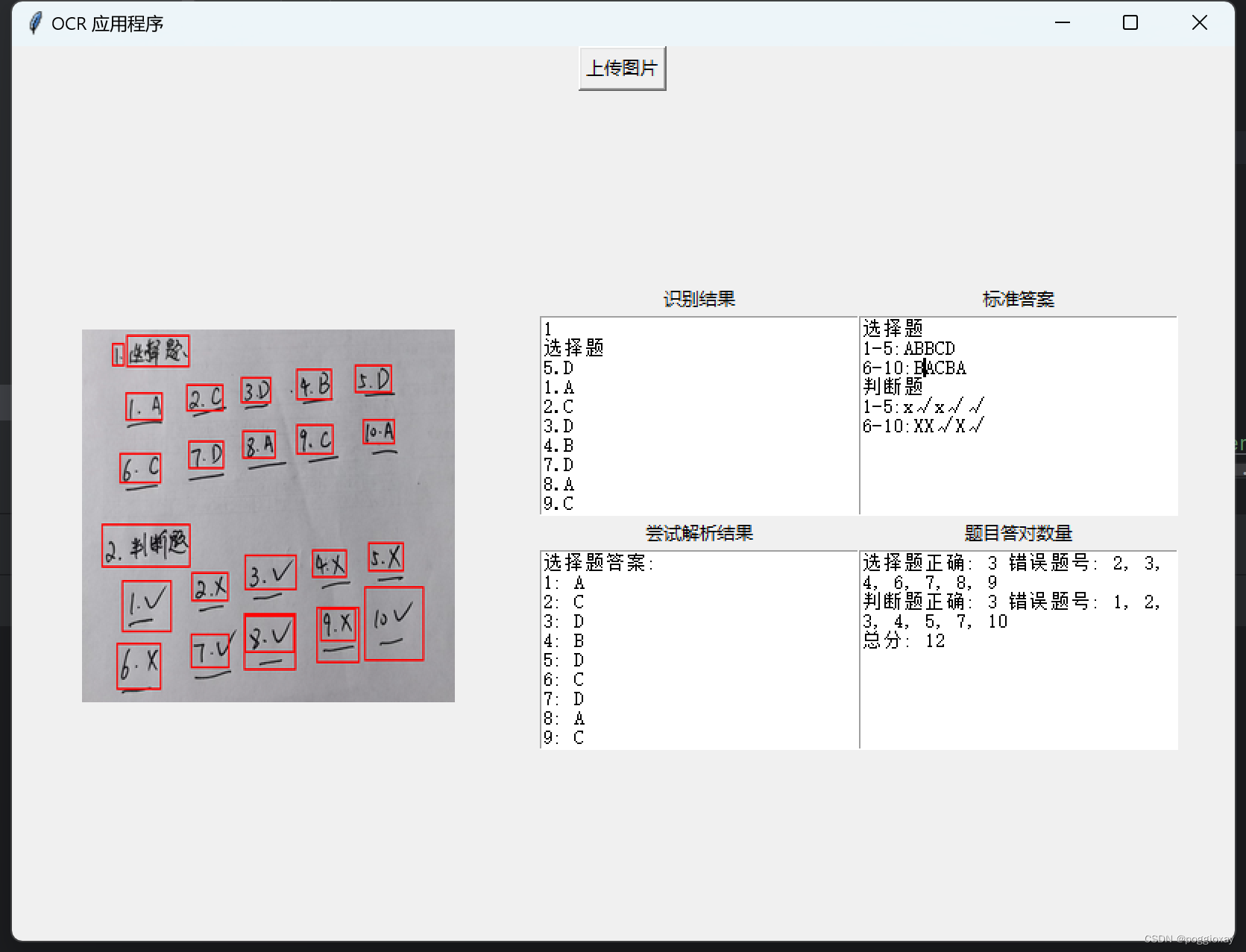
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.glev.cn/tnews/1671.html








最新文章
-

可以分期买手机的平台(可以分期买手机的平台二手)
2025-12-15 -
安卓手机怎么用(安卓手机怎么用CarPlay车机)
2025-12-15 -
手机壁纸动画(手机壁纸动画熊猫在哪里设置)
2025-12-15 -
如何手机双清(如何手机双清教程图片)
2025-12-15 -
安兔兔手机跑分排行(安兔兔手机性能排行)
2025-12-15 -
手机nfc模拟门禁卡(手机nfc模拟门禁卡原理)
2025-12-15 -
下载手机玲声(下载到手机上)
2025-12-15 -
中兴手机教程(中兴ⅴ2022手机)
2025-12-15
热门文章
-

饺子的传说
2025-03-16 -

快手看广告领金币怎么赚钱?看200个广告日赚百元教学攻略
2024-12-19 -

手机连接有线网络(手机连接有线网络设置方法)
2025-02-08 -

传承百年的非遗王源吉铁锅,不粘、不生锈、超耐用!
2025-03-05 -

手机尾插更换教程(手机尾插更换教程视频VOVI27)
2025-02-15 -

百度推广运营获客渠道有哪些
2024-12-07 -

宁波seo:独立搜索引擎的成功案例
2024-12-08 -

百度竞价代运营怎么收费的?揭秘行业内幕与收费标准
2024-12-07