截图识别对比:CnOCR与PaddleOCR

想使用PyAutoGUI做界面自动化,需要一个ocr库识别压测软件的文字,然后获取定位。现在找到了CnOCR与PaddleOCR,都安装来试试看,哪一个更适合我的需求,这里对这俩库进行对比。 本机环境:

两个库都有详细的安装步骤,有报错就去百度,安装对应的库就好了。 特别提醒安装Polygon3报错:Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”: Microsoft C++ Build Tools - Visual Studio。 不要去安Visual Studio,去https://www.lfd.uci.edu/~gohlke/pythonlibs/下载一个Polygon3-3.0.9.1-cp39-cp39-win_amd64.whl包,手动安就好了。
CnOCR:
CnOCR 是 Python 3 下的文字识别(Optical Character Recognition,简称OCR)工具包,支持简体中文、繁体中文(部分模型)、英文和数字的常见字符识别,支持竖排文字的识别。自带了20+个训练好的识别模型,适用于不同应用场景,安装后即可直接使用。同时,CnOCR也提供简单的训练命令供使用者训练自己的模型。 开源地址:https://gitee.com/cyahua/cnocr/ 安装使用国内源快一点
PaddleOCR(飞桨)
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR和PP-Structure,并打通数据生产、模型训练、压缩、预测部署全流程。 开源地址:https://gitee.com/paddlepaddle/PaddleOCR 安装命令:
待识别原图: 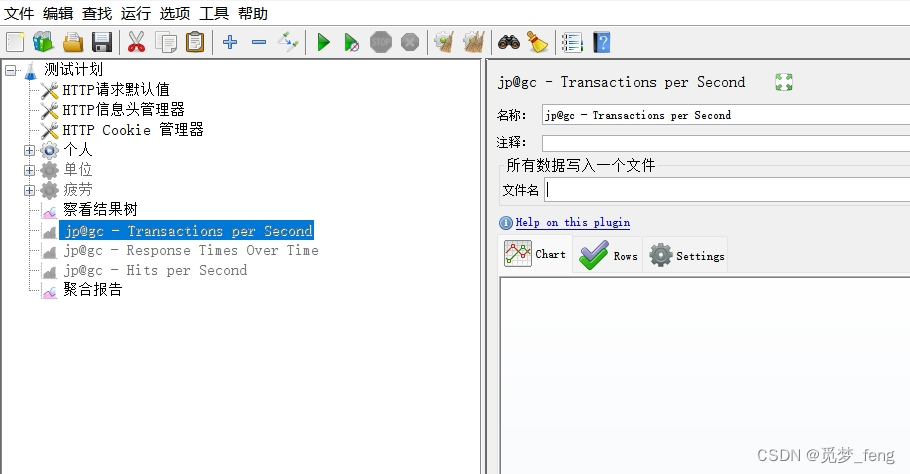
CnOCR:
使用还是挺方便,有几个模型选用,我主要是识别软件截图,就使用了doc-densenet_lite_136-gru的文档图片模型,试了几个图片,比通用模型要好一点点。
识别出的文字: 其中score是:识别结果的得分(置信度),取值范围为 [0, 1];得分越高表示越可信 从结果对比原图,有较多的图标被识别成文字,我需要点击的【jp@gc - Transactions per Second】等标题,置信度不高。
PaddleOCR(飞桨)
就是默认设置,示例代码
识别出的文字: 速度慢点,但是内容明细精准许多。
有个飞桨的可视化图 
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.glev.cn/tnews/1993.html








最新文章
-

可以分期买手机的平台(可以分期买手机的平台二手)
2025-12-15 -
安卓手机怎么用(安卓手机怎么用CarPlay车机)
2025-12-15 -
手机壁纸动画(手机壁纸动画熊猫在哪里设置)
2025-12-15 -
如何手机双清(如何手机双清教程图片)
2025-12-15 -
安兔兔手机跑分排行(安兔兔手机性能排行)
2025-12-15 -
手机nfc模拟门禁卡(手机nfc模拟门禁卡原理)
2025-12-15 -
下载手机玲声(下载到手机上)
2025-12-15 -
中兴手机教程(中兴ⅴ2022手机)
2025-12-15
热门文章
-

饺子的传说
2025-03-16 -

快手看广告领金币怎么赚钱?看200个广告日赚百元教学攻略
2024-12-19 -

手机连接有线网络(手机连接有线网络设置方法)
2025-02-08 -

传承百年的非遗王源吉铁锅,不粘、不生锈、超耐用!
2025-03-05 -

手机尾插更换教程(手机尾插更换教程视频VOVI27)
2025-02-15 -

百度推广运营获客渠道有哪些
2024-12-07 -

宁波seo:独立搜索引擎的成功案例
2024-12-08 -

百度竞价代运营怎么收费的?揭秘行业内幕与收费标准
2024-12-07