【实战案例】python爬取百度图片

网络爬虫的本质就是模拟客户端发送请求,一个爬虫的基本开发流程包含五步: 1、明确目标数据
2、分析数据的请求流程
3、模拟发送请求
4、解析数据
5、数据持久化
我们要下载的是百度图片首页中的图片 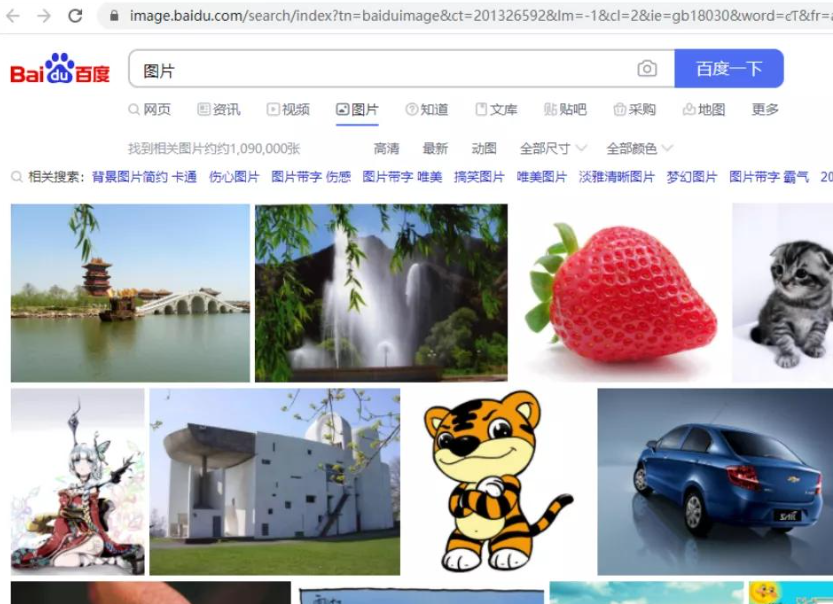 网页中的图片是浏览器通过 http 请求下载回来的。
网页中的图片是浏览器通过 http 请求下载回来的。
浏览器会先下载图片的 url,再通过 url 下载图片。
所以我们只要找到图片 url 的 http 请求即可。
一般情况下,页面中的图片 url 就包含在页面的 HTML 文档中,使用谷歌浏览器开发者调试工具获取图片的 url 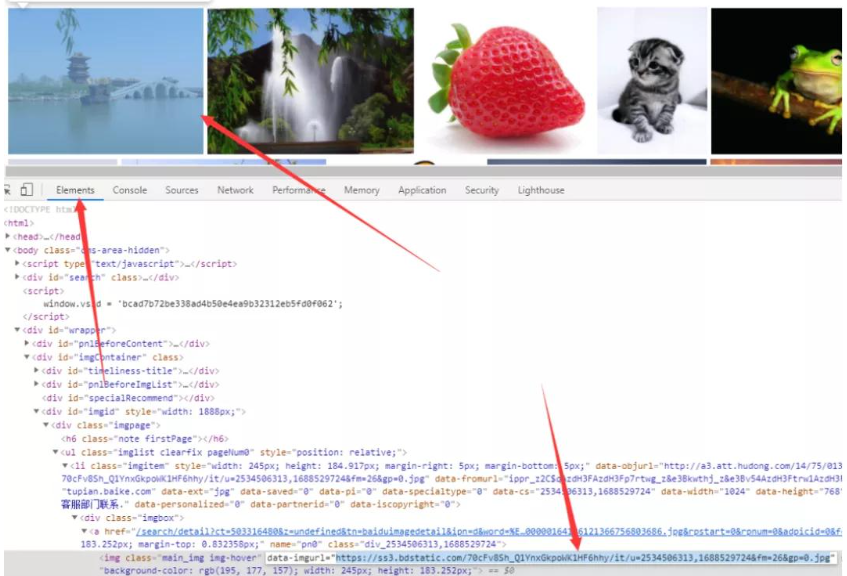 然后右键查看网页源文件可以查看当前页面的 HTML 文档
然后右键查看网页源文件可以查看当前页面的 HTML 文档
ctrl+f 调出搜索框,把前面找到的图片的 url 粘贴进来,果然发现了 url 就在 HTML 中 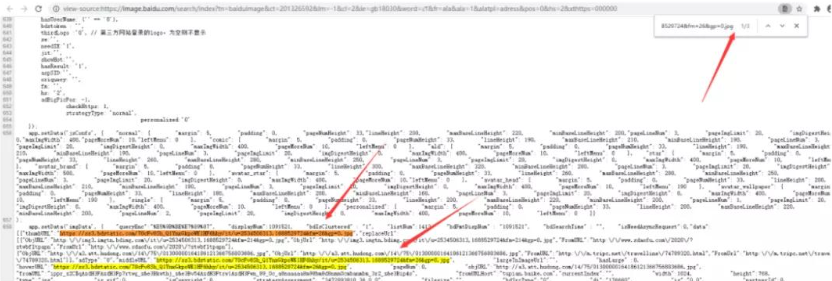 为了稳妥可以多找几张图片的 url 测试。发现页面中的前 30 张图片的 url 都在 HTML 文档中。
为了稳妥可以多找几张图片的 url 测试。发现页面中的前 30 张图片的 url 都在 HTML 文档中。
在 HTTP 协议中信息以二进制的形式进行传输的,我们需要借助工具来分析 HTTP 请求。常用工具有,谷歌浏览器和 fiddler。
fiddler 的使用和安装相对复杂,谷歌浏览器可以满足大部分的请求流程分析,这里主要介绍谷歌浏览器。
谷歌浏览器提供了开发者调试工具,能够对浏览器的 HTTP 请求进行监控,按功能键 F12 即可打开工具界面,功能窗口如下:
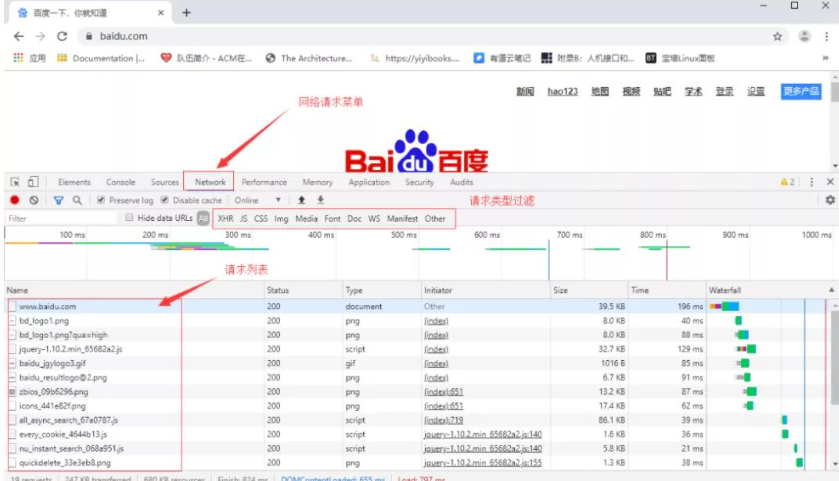 点击某个具体的请求后
点击某个具体的请求后 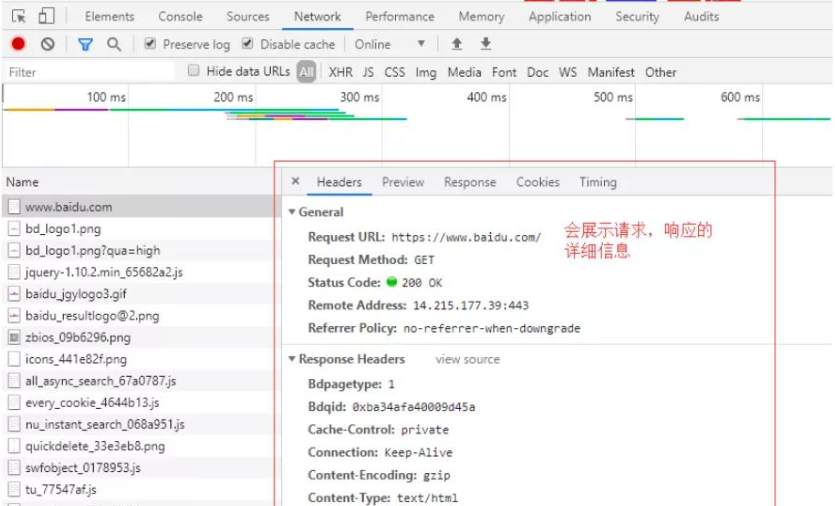 我们这个案例中的请求就是网页的请求
我们这个案例中的请求就是网页的请求 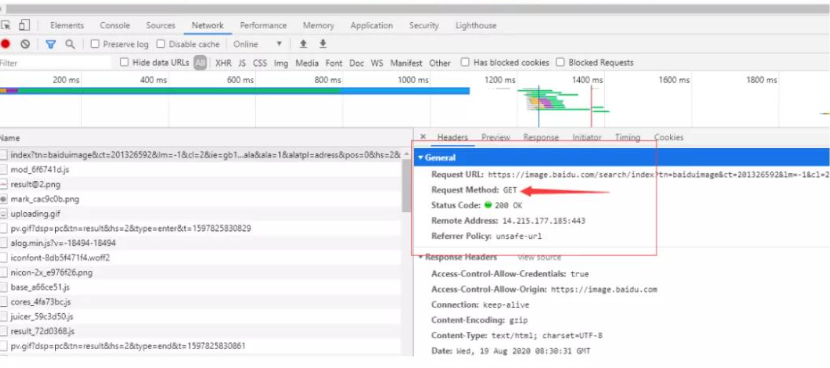
分析请求流程的目的找到目标资源的 http 请求,根据前面学习的 HTTP 协议知识,分析请求流程的具体信息是: 1、请求方法:get
2、url: https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%CD%BC%C6%AC&fr=ala&ala=1&alatpl=adress&pos=0&hs=2&xthttps=000000
3、请求头:当前可以忽略
4、请求数据:无
分析清楚目标资源的请求过程后,就需要通过代码模拟发送请求。

上面我们通过使用 socket 实现了一个非常简单的请求的发送,可以看到代码比较复杂,如果需要传递更多信息,处理起来会更繁琐,费时费力。
python 提供了很多的库,将发送 HTTP 请求的细节进行了封装,只需要进行简单的调用就可以实现各种 http 请求的发送,常用的库有:
- urllib urllib 是一个用来处理网络请求的 python 标准库
- urllib3 urllib3 是一个基于 python3 的功能强大,友好的 http 客户端。越来越多的 python 应用开始采用 urllib3.它提供了很多 python 标准库里没有的重要功能。
- requests 牛逼
使用 requests 发送请求 
响应正文及响应数据一般分为两大类,文本数据和二进制数据。
其中文本数据又分为 HTML 和 JSON(注:主要指爬虫目标数据,js,CSS 等也属于文本数据)。
二进制数据主要指各种音频,视频,其他文件等。
对于二进制数据一般不需要特殊处理。
HTML 解析
今天的案例数据包含在 HTML 文档中,所以需要解析 HTML
解析 HTML 的常用方法有两种:
1、正则表达式
2、HTML 解析库
爬虫爬取到的数据需要存储起来,对于少量的数据,生成相应的文件,例如 Excel,cvs 等。
对于图片,视频等二进制文件也是以文件的形式保存。
如果要保存大量的文本信息,例如商品信息,订单信息等,就需要存储到数据库中。

如果有想学习爬虫的小伙伴,这里给大家分享一份Python爬虫学习资料和公开课,里面的内容都是适合零基础小白的笔记和资料,超多实战案例,不懂编程也能听懂、看懂。需要的话扫描下方二维码免费获得,让我们一起学习!
除了上述分享,如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
这里给大家展示一下我进的群和最近接单的截图

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取,也可以内推群哦~
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
 ### 1.Python学习路线
### 1.Python学习路线


2.Python基础学习
01.开发工具

02.学习笔记

03.学习视频

3.Python小白必备手册

4.数据分析全套资源

5.Python面试集锦
01.面试资料


02.简历模板

因篇幅有限,仅展示部分资料,添加上方即可获取👆
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.glev.cn/tnews/2106.html
上一篇
高德地图怎么添加店铺位置








最新文章
-

可以分期买手机的平台(可以分期买手机的平台二手)
2025-12-15 -
安卓手机怎么用(安卓手机怎么用CarPlay车机)
2025-12-15 -
手机壁纸动画(手机壁纸动画熊猫在哪里设置)
2025-12-15 -
如何手机双清(如何手机双清教程图片)
2025-12-15 -
安兔兔手机跑分排行(安兔兔手机性能排行)
2025-12-15 -
手机nfc模拟门禁卡(手机nfc模拟门禁卡原理)
2025-12-15 -
下载手机玲声(下载到手机上)
2025-12-15 -
中兴手机教程(中兴ⅴ2022手机)
2025-12-15
热门文章
-

饺子的传说
2025-03-16 -

快手看广告领金币怎么赚钱?看200个广告日赚百元教学攻略
2024-12-19 -

手机连接有线网络(手机连接有线网络设置方法)
2025-02-08 -

传承百年的非遗王源吉铁锅,不粘、不生锈、超耐用!
2025-03-05 -

手机尾插更换教程(手机尾插更换教程视频VOVI27)
2025-02-15 -

百度推广运营获客渠道有哪些
2024-12-07 -

宁波seo:独立搜索引擎的成功案例
2024-12-08 -

百度竞价代运营怎么收费的?揭秘行业内幕与收费标准
2024-12-07