【OpenCV/C++】KNN算法识别数字的实现原理与代码详解

1.1 KNN原理介绍
KNN算法,即K最近邻算法,顾名思义其原理是当要预测一个新的值x的时候,根据离他最近的K个点大多属于什么类别来判断x属于哪个类别。
zzzzMing -大数据技术-深入浅出KNN算法
K=3时,x最近的三个图形包括两个三角形、一个圆形,因为2>1,所以x更有可能是三角形。
K=5时,x最近的五个图形包括两个三角形、三个圆形,因为3>2,所以x更有可能是圆形。
同理类比到图像识别方面,使用KNN算法前我们需要有大量的训练样本,并且知道每个样本所属的类别。(例如大量的数字图片,并且知道每个图片代表数字几)。当我们要识别数字时,本质上就是在训练样本中找与要识别的图像最接近的K个样本,然后统计出K个样本中出现最多的数字是哪个,那就是要识别的数字。
1.2 KNN的关键参数
① 寻找多少最近邻样本 - K的选择
K值决定着图像识别过程中,寻找的最近邻的图像个数,由上面的例子可以看出,选择不同的K,识别结果可能完全不同,因此K值是KNN算法中最关键的参数之一,它直接影响着模型的性能。
K值如果过小,那么此时识别结果就会很受样本质量的影响。如果训练样本存在某些错误或噪音,而寻找最近邻样本时正好找到了这些项,那么识别结果一定是错的,而增大K值,多寻找样本,会有效降低样本噪音的影响。
K值如果过大,假设K值等于训练样本数,那么无论要识别的图片是什么,识别结果都是样本中最多的那个类别。
那么K值应该如何选择呢?理论上来说K值与识别准确率的关系是存在一个极值的,可以通过多次实验,根据结果选择一个最好的K值。(例如K=3时准确率72;K=5时准确率91;K=8时准确率81,那么选择K=5会是一个相对较好的选择)
② 如何判断“接近”程度 - 距离的计算 距离计算函数一般使用曼哈顿距离或欧氏距离。
曼哈顿距离就是样本特征每一个维度的差值之合。(对应于图像,就是两图像每个像素做差) 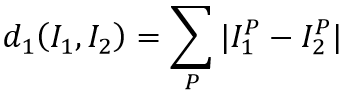
欧式距离是样本特征在每一个维度上差值的平方和的根。 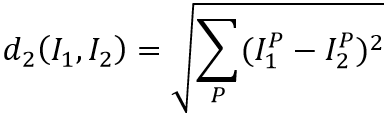
KNN算法识别手写数字的源程序 - 点此下载 注:只包括KNN算法部分,关于图片ROI区域截取请参考《一文详解opencv摄像头数字识别》
2.1 训练过程代码详解
首先,我们要获得训练样本。OpenCV安装目录中给我们提供了手写数字的样本图片。这个图片中每个数字有5x100个样本,并且每个数字所占的像素均为20x20,因此可以从这个图片中提取我们需要的训练样本。
我们按列裁剪样本图片,每裁剪一个样本,就将其添加到data中,并同时将对应的数字添加到lable中。这样一来,我们就获得了图片和数字一一对应的data和lable数据。
利用这个训练样本就可以创建KNN模型了。
如果需要测试模型的识别准确度,可以从刚才获得的5000个样本中,选择前3000个样本作为训练数据,后2000个作为测试数据。用KNN模型计算测试数据的在样本中的识别正确情况。
2.2 预测分类的实现过程
训练样本制作完毕后,预测分类就非常简单了,将要识别的图像读取进来,进行二值化处理,然后调整大小到与样本图片一样大(20x20)。将处理好的图片push到test中,就可以直接使用刚才创建的KNN模型进行预测了。
KNN算法识别印刷数字的源程序 -点此下载
注:只包括KNN算法部分,关于图片ROI区域截取请参考《一文详解opencv摄像头数字识别》
2.1 训练过程
识别印刷体数字与识别手写数字的原理相同,只是训练样本有区别。这里我制作了1000张不同字体的训练样本,加载方式例如:
本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕,E-mail:xinmeigg88@163.com
本文链接:http://www.glev.cn/tnews/2232.html








最新文章
-

可以分期买手机的平台(可以分期买手机的平台二手)
2025-12-15 -
安卓手机怎么用(安卓手机怎么用CarPlay车机)
2025-12-15 -
手机壁纸动画(手机壁纸动画熊猫在哪里设置)
2025-12-15 -
如何手机双清(如何手机双清教程图片)
2025-12-15 -
安兔兔手机跑分排行(安兔兔手机性能排行)
2025-12-15 -
手机nfc模拟门禁卡(手机nfc模拟门禁卡原理)
2025-12-15 -
下载手机玲声(下载到手机上)
2025-12-15 -
中兴手机教程(中兴ⅴ2022手机)
2025-12-15
热门文章
-

饺子的传说
2025-03-16 -

快手看广告领金币怎么赚钱?看200个广告日赚百元教学攻略
2024-12-19 -

手机连接有线网络(手机连接有线网络设置方法)
2025-02-08 -

传承百年的非遗王源吉铁锅,不粘、不生锈、超耐用!
2025-03-05 -

手机尾插更换教程(手机尾插更换教程视频VOVI27)
2025-02-15 -

百度推广运营获客渠道有哪些
2024-12-07 -

宁波seo:独立搜索引擎的成功案例
2024-12-08 -

百度竞价代运营怎么收费的?揭秘行业内幕与收费标准
2024-12-07